Medizinische Forschungsvorhaben, Studien und Register greifen zur Beantwortung ihrer Forschungsfragen zunehmend auf bereits vorhandene medizinische Daten aus der Routineversorgung, von Krankenkassen oder Registern zurück. Diese Daten werden im Laufe der Zeit in verschiedenen Einrichtungen – etwa in Kliniken, bei niedergelassenen Ärztinnen und Ärzten oder in medizinischen Registern – erhoben. Um immer komplexere Fragestellungen beantworten zu können, ist eine Zusammenführung dieser Daten erforderlich.
Da nicht immer ein eindeutiger Identifikator über alle Datenquellen hinweg vorhanden ist, erfolgt die Zusammenführung häufig anhand identifizierender Daten wie Vorname, Nachname und Geburtsdatum. Aus Datenschutzgründen ist es jedoch nicht immer zulässig oder erwünscht, diese Identitätsdaten zentral im Klartext zu verarbeiten.
Hier setzt das Privacy-Preserving Record Linkage (PPRL) an, bei dem die Daten in verschlüsselter Form abgeglichen werden – ohne dass die Identität einer Person offengelegt werden muss. Die zentrale Herausforderung besteht darin, die medizinischen Daten sicher und korrekt zu verknüpfen. Sowohl Homonymfehler (Daten zu mehreren Personen werden fälschlicherweise verknüpft), als auch Synonymfehler (Daten zu einer Person wurden nicht verknüpft, es entstehen Dubletten) sollen vermieden werden. Da sich identifizierende Daten ändern können – etwa durch Umzug oder Heirat – oder Fehler enthalten sein können (z. B. Tippfehler oder Zahlendreher), müssen auch Datensätze mit hoher Ähnlichkeit zusammengeführt werden können.
Integrationen
Föderierte Treuhandstelle
Die föderierte Treuhandstelle oder federated Trusted Third Party (fTTP) übernimmt das föderierte Record Linkage. Dabei kommen Verfahren zum Einsatz, welche den Abgleich von verschlüsselten Daten ermöglichen und Datensätze auch dann korrekt zu einer Person zusammenführen können, wenn diese z.B. durch Fehler unterschiedlich sind. Darüber hinaus wird eine übergreifende und einheitliche Pseudonymisierung ermöglicht. Die Umsetzung von Betroffenenrechten oder die Möglichkeit der Re-Kontaktierung ist wie mit anderen Treuhandstellenmodellen möglich. Der Use Case entscheidet, welches Modell (PPRL oder Klartext) besser für ein Projekt geeignet ist. Hierfür sind der gewünschte Grad an Sicherheit und die vorliegende Datenqualität relevant.
Lokale und zentrale Treuhandstellen
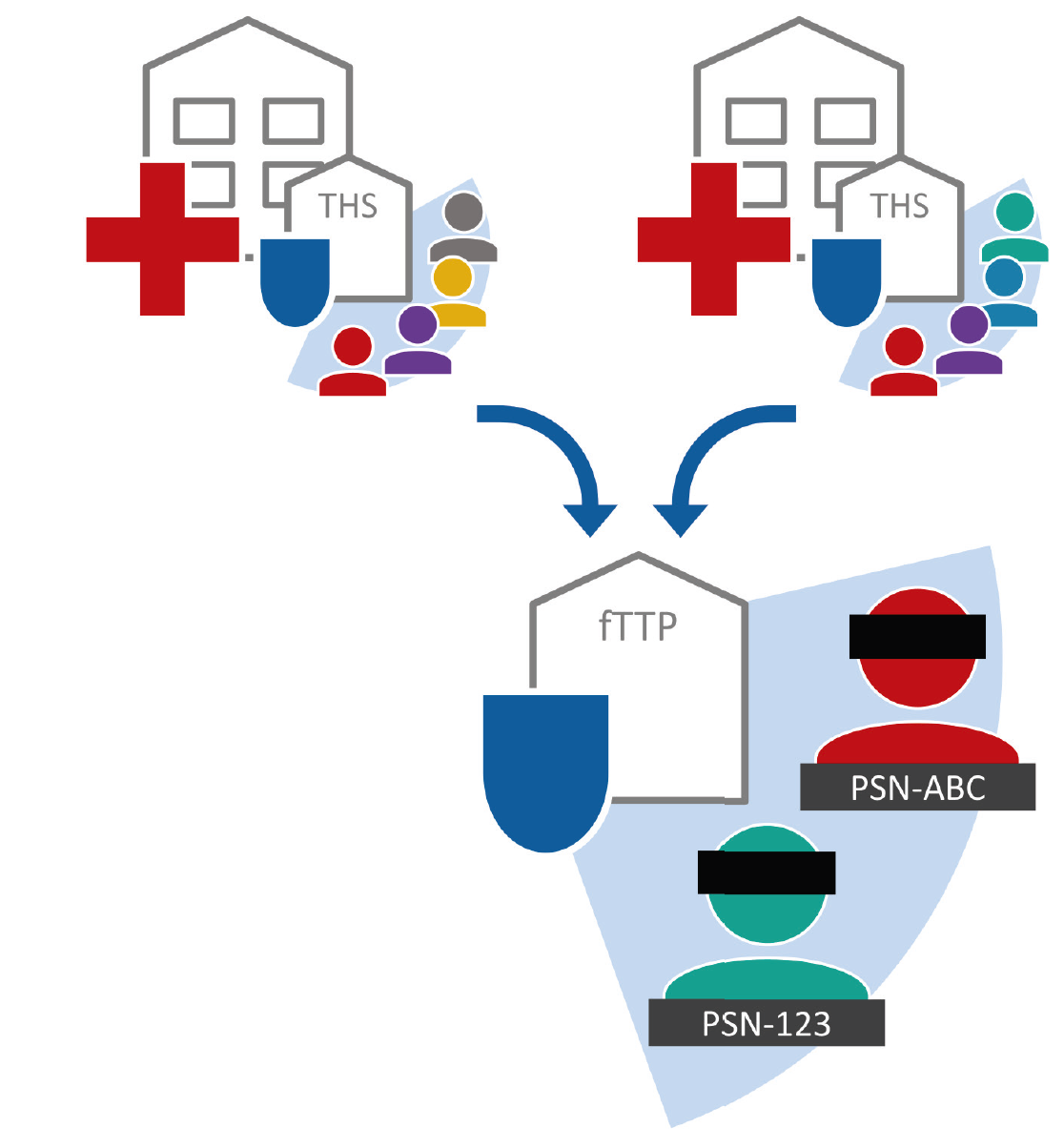
Lokale und zentrale Treuhandstellen verwalten die identifizierenden Daten, Pseudonyme, Einwilligungen, Widerrufe und Widersprüche innerhalb eines Standorts (z.B. Universitätsklinik) oder zu mehreren Standorten (z.B. mehrere Studienzentren einer Studie). Die identifizierenden Daten werden in der Regel als Klarinformationen in einem Identitätsmanagement miteinander abgeglichen und so ein Record Linkage innerhalb dieser Treuhandstelle umgesetzt. Dabei werden im Pseudonymmanagement die Pseudonyme z.B. für die Systeme am Standort oder z.B. die Datenausleitungen einer Studie erzeugt und verwaltet. Mit einem Einwilligungsmanagement werden Einwilligungen und Widerrufe verwaltet und umgesetzt, um den Betroffenenrechten gerecht zu werden. In übergreifenden Forschungsvorhaben mit übergreifenden Record Linkage dienen lokale und zentrale Treuhandstellen zur dezentralen Datenhaltung der Klarinformationen und sind verantwortlich für die einheitliche Verschlüsselung dieser Daten, wenn ein übergreifendes Privacy-Preserving Record Linkage umgesetzt werden soll. Dies ist die Grundlage, um übergreifend diese Treuhandstellen bzw. Standorte über die fTTP miteinander zu vernetzen.
Föderiertes Record Linkage
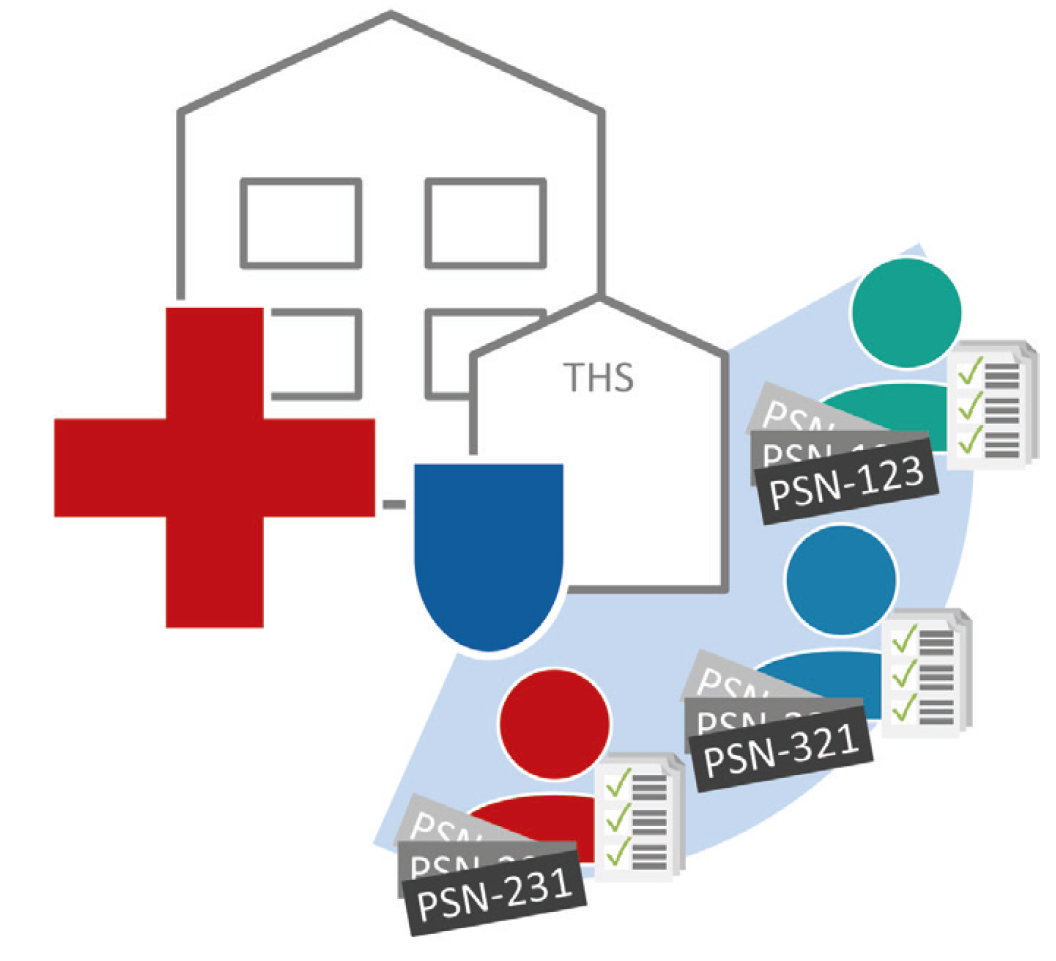
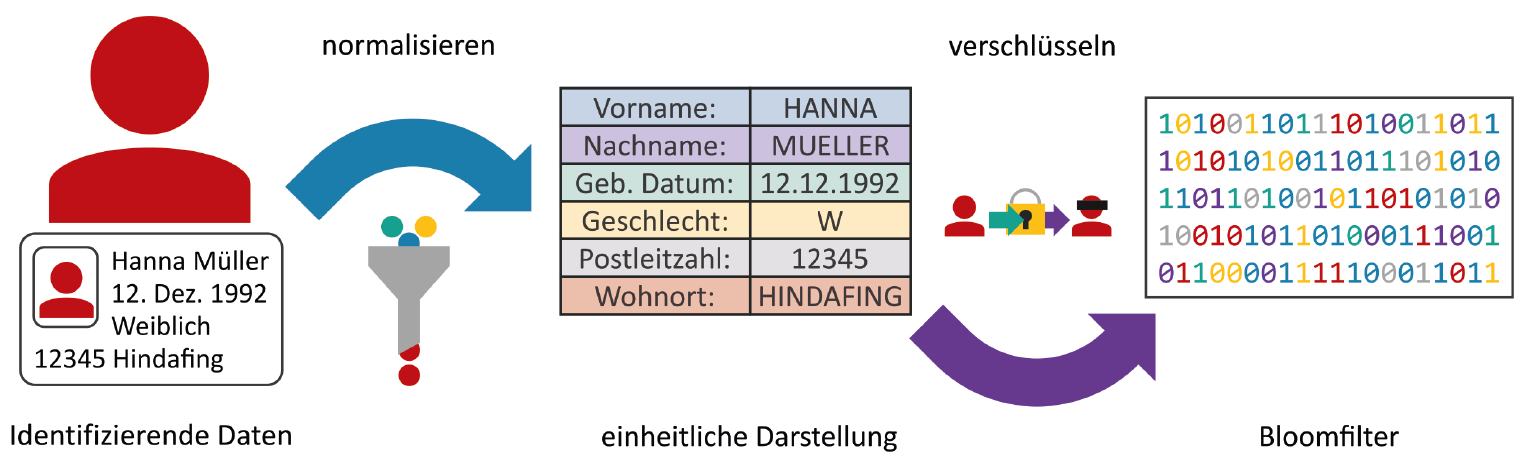
Die fTTP vernetzt dezentrale Strukturen wie lokale oder zentrale Treuhandstellen und ermöglicht den verschlüsselten Abgleich der dort vorliegenden identifizierenden Daten. Die angebundenen Standorte verschlüsseln die identifizierenden Daten projektspezifisch zu sogenannten Bloomfiltern – initial mit Nullen besetzte Bit-Vektoren. Die zu codierenden Daten werden dabei so umgerechnet, dass mehrere Positionen im Bit-Vektor auf Eins gesetzt werden. Dabei werden meist mehrere Daten zu einer Person in einem Bloomfilter codiert. Mittels weiterer Härtungsverfahren wird der Bloomfilter abgesichert, sodass keine Rückschlüsse mehr auf die ursprünglichen Daten gezogen werden können. Bloomfilter sind ein gut erforschtes und etabliertes Verfahren. Auch große Datenbestände lassen sich damit performant abgleichen, zum Beispiel in Trusted Research Environements (TRE). Da Bloomfilter nur miteinander verglichen werden können, wenn diese auf dieselbe Weise erzeugt wurden, legen die datengebenden Standorte eine
projektspezifische Konfiguration fest. Dies umfasst neben einer einheitlichen Normalisierung der Ausgangsdaten, angewandter Verfahren und Härtungen meist auch zusätzliche Geheimnisse, welche in die Berechnung mit einfließen. Die fTTP kennt die verwendete Konfiguration nicht und erhält nur die Bloomfilter, welche auf Ähnlichkeit oder Übereinstimmung geprüft werden. Je nachdem werden Pseudonyme vergeben und den jeweiligen Personen zugeordnet, welche über die Bloomfilter abgebildet sind. Dieselbe Person erhält je nach projektspezifischer Pseudonymisierung dasselbe übergreifende, oder ein standortspezifisches Pseudonym. Der Abgleich erzielt dabei vergleichbare Ergebnisse, als wären die Daten als Klarinformationen verglichen worden. Eine klassische Dublettenauflösung, wie sie mit Klardaten erreicht wird, kann mittels Bloomfilter jedoch nicht umgesetzt werden. Sollen solche unklaren Fälle dennoch aufgelöst werden, so kann bei Bedarf eine Clearingstelle zugeschaltet werden.
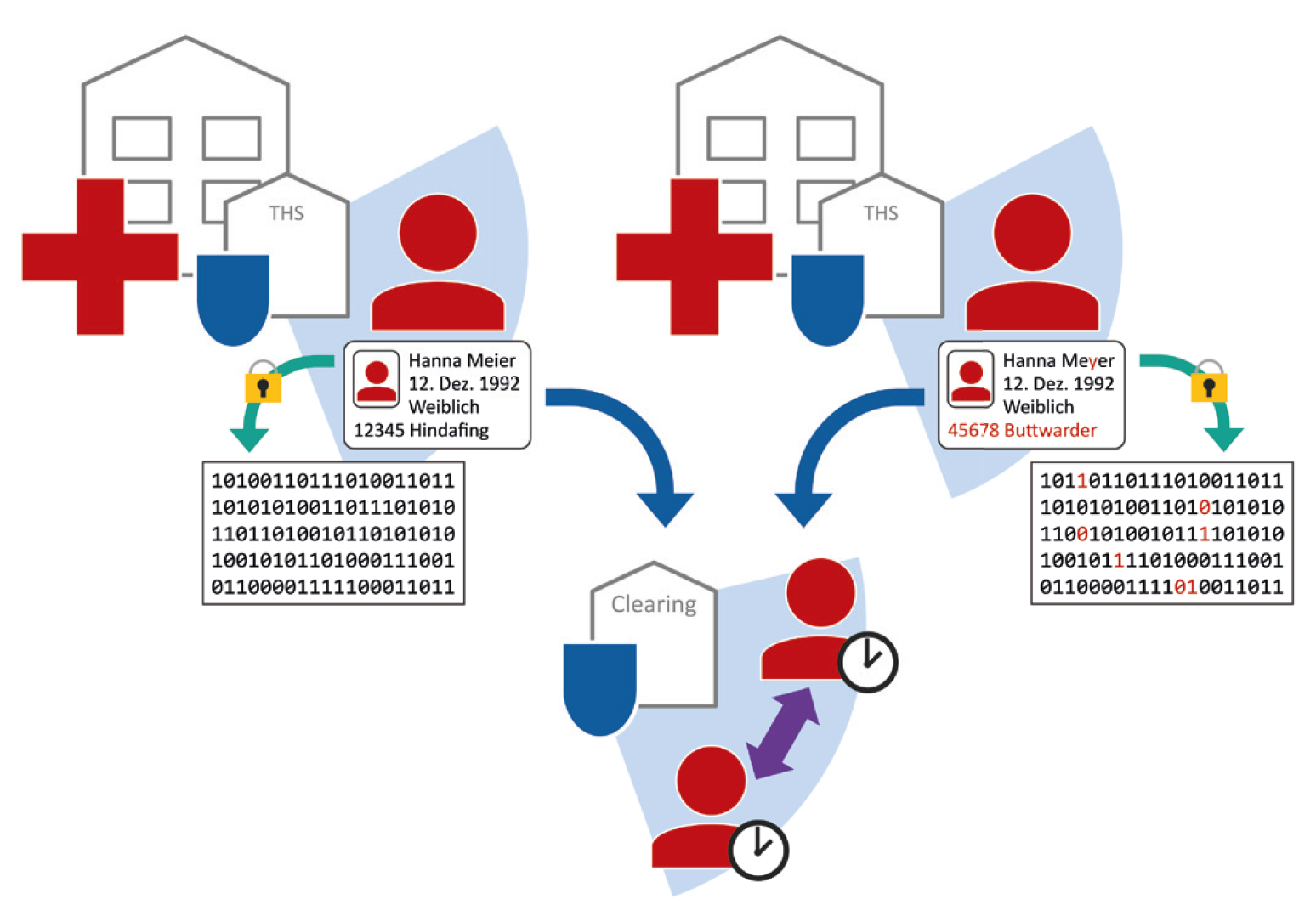
Die Clearingstelle
In unsicheren Fällen, in denen Bloomfilter zwar sehr ähnlich sind, jedoch hinreichend unterschiedlich sind, sodass diese nicht zweifelsfrei derselben Person zugeordnet werden können, kann ein zusätzliches Clearing erwünscht sein. Hierzu kann projektspezifisch eine Clearingstelle dazugeschaltet werden, welche in Einzelfällen die Klarinformationen erhält, um mögliche Dubletten zweifelsfrei aufzulösen. Hierzu übermitteln die Standorte nur die betroffenen Datensätze, sodass in der Clearingstelle die Klardaten geprüft werden können. Nachdem die Dublettenauflösung abgeschlossen wurde, werden die Klardaten restlos und unwiederbringlich in der Clearingstelle gelöscht. Nur die Information, ob Bloomfilter zur selben oder zu verschiedenen Personen gehören, wird in der fTTP gespeichert. Dabei sind Bloomfilter und Klardaten zu jeder Zeit getrennt, sodass diese nicht zusammengeführt werden können.
API und Schnittstelle
Die Dokumentation der HL7 FHIR Schnittstelle der fTTP (v1) steht online zur Verfügung.
Die fTTP-Schnittstelle absolvierte erfolgreich das offizielle HL7 Kommentierungsverfahren im Mai 2023 (Ballot).
Dokumentation
Förderungen und Publikationen
Die Umsetzung der MII-Konzepte für föderiertes Record Linkage wurden erstmals im Rahmen des NUM-CODEX-Projektes durch Etablierung der fTTP realisiert. Diese Arbeit wurde vom Deutschen Bundesministerium für Bildung und Forschung (BMBF) gefördert (Förderkennzeichen 01KX2021) und im Rahmen von NUM-RDP (BMBF Förderkennzeichen 01KX2121) um Betriebskonzepte erweitert. Darüber hinaus wird die Erweiterung der fTTP-Ansätze im Sinne einer Generalisierung im Rahmen des Merge´n´Dice Projektes (Förderung Datentreuhandmodelle durch VDI VDE IT, Förderkennzeichen 16DTM231) vorangebracht.
Ausgewählte Publikationen