![]() Um Forschungsdaten aus verschiedenen Projekten und Studien zu verknüpfen sind ein Record Linkage und eine eindeutige Kennung erforderlich. Neben der Verwaltung personenidentifizierender Daten (IDAT) müssen einzelne Kennungen der Quellsysteme (z.B. Labore, Studienzentralen, etc.) der korrekten Person zugeordnet werden. Da IDAT unvollständig oder fehlerhaft sein können, ist ein fehlertolerantes und nachvollziehbares Record Linkage erforderlich. Alle diese Aufgaben werden durch den E-PIX® übernommen.
Um Forschungsdaten aus verschiedenen Projekten und Studien zu verknüpfen sind ein Record Linkage und eine eindeutige Kennung erforderlich. Neben der Verwaltung personenidentifizierender Daten (IDAT) müssen einzelne Kennungen der Quellsysteme (z.B. Labore, Studienzentralen, etc.) der korrekten Person zugeordnet werden. Da IDAT unvollständig oder fehlerhaft sein können, ist ein fehlertolerantes und nachvollziehbares Record Linkage erforderlich. Alle diese Aufgaben werden durch den E-PIX® übernommen.
Der E-PIX® ermöglicht ein wahrscheinlichkeitsbasiertes Record Linkage und erzeugt je Forschungsvorhaben und Person eine eindeutige Kennung (Master Patient Index). Der E-PIX® kann unterschiedliche Ausprägungen von IDAT einer Person verwalten und erlaubt mögliche Synonymfehler (Doppler) automatisch zu erkennen. Dies erfolgt anhand frei definierbarer Parameter (z.B. Vorname, Nachname, Geburtsdatum, KVNR, Adressinformationen). Dabei kann beim automatisierten Abgleich zwischen mehreren Algorithmen gewählt werden. Projektspezifische Validierungen verhindern die Eingabe invalider Daten und erhöhen die Datenqualität bereits bei der Dateneingabe. Mögliche Synonymfehler werden protokolliert und können mithilfe des E-PIX® aufgelöst werden. Standortübergreifende Forschungsvorhaben erfordern einen besonderen Schutz der IDAT. Deshalb ermöglicht der E-PIX® ebenso ein Privacy-Preserving Record Linkage (PPRL) durch die Erzeugung und den Vergleich von kodierten IDAT. Der E-PIX® kann in lokalen, dezentralen und zentralen Infrastrukturen eingesetzt werden.
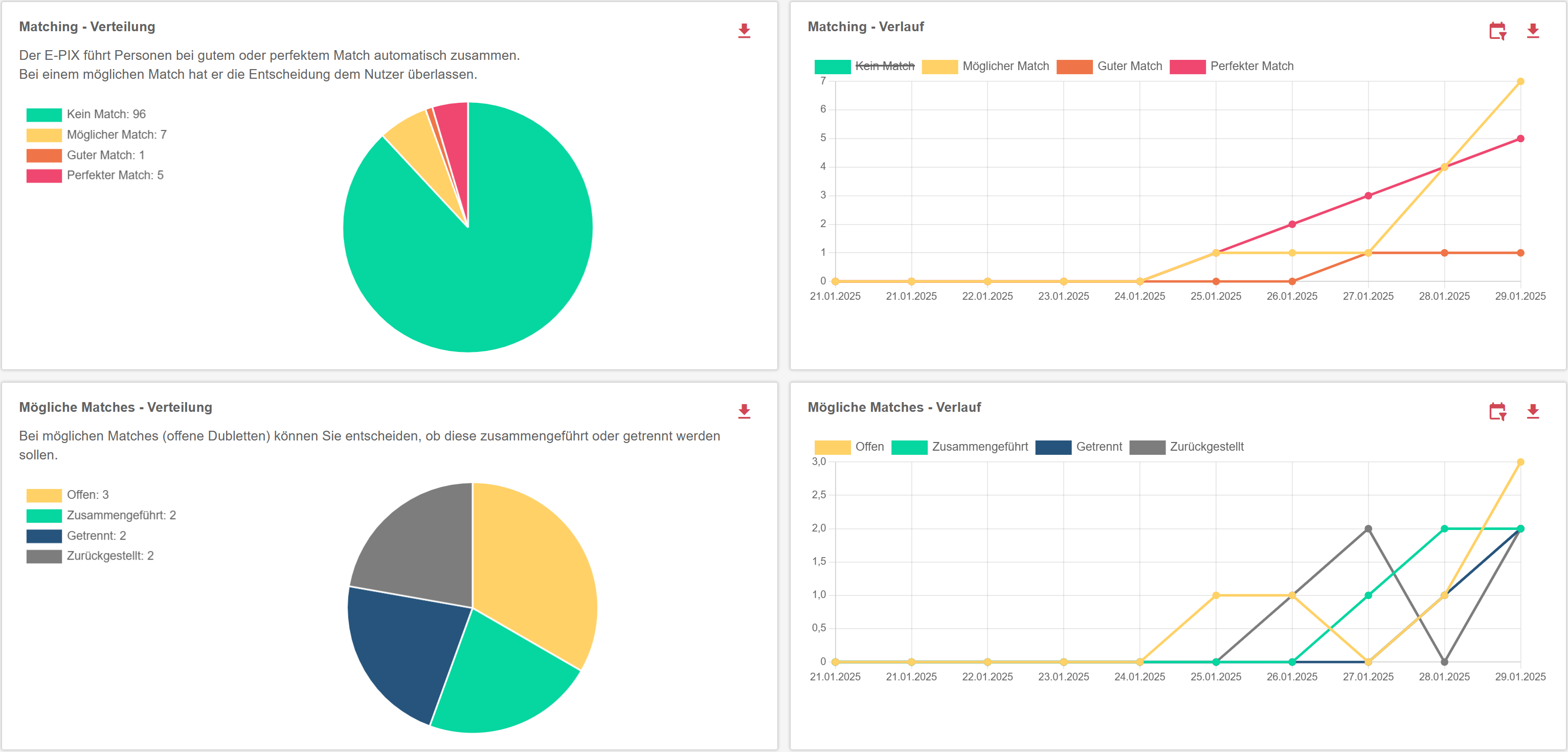
Dashboard
Das Dashboard liefert einen schnellen Überblick zu Anzahlen von Personen, Identitäten und Dubletten. Alle Werte sind grafisch aufbereitet und können bei Bedarf direkt aus dem Dashboard exportiert werden.
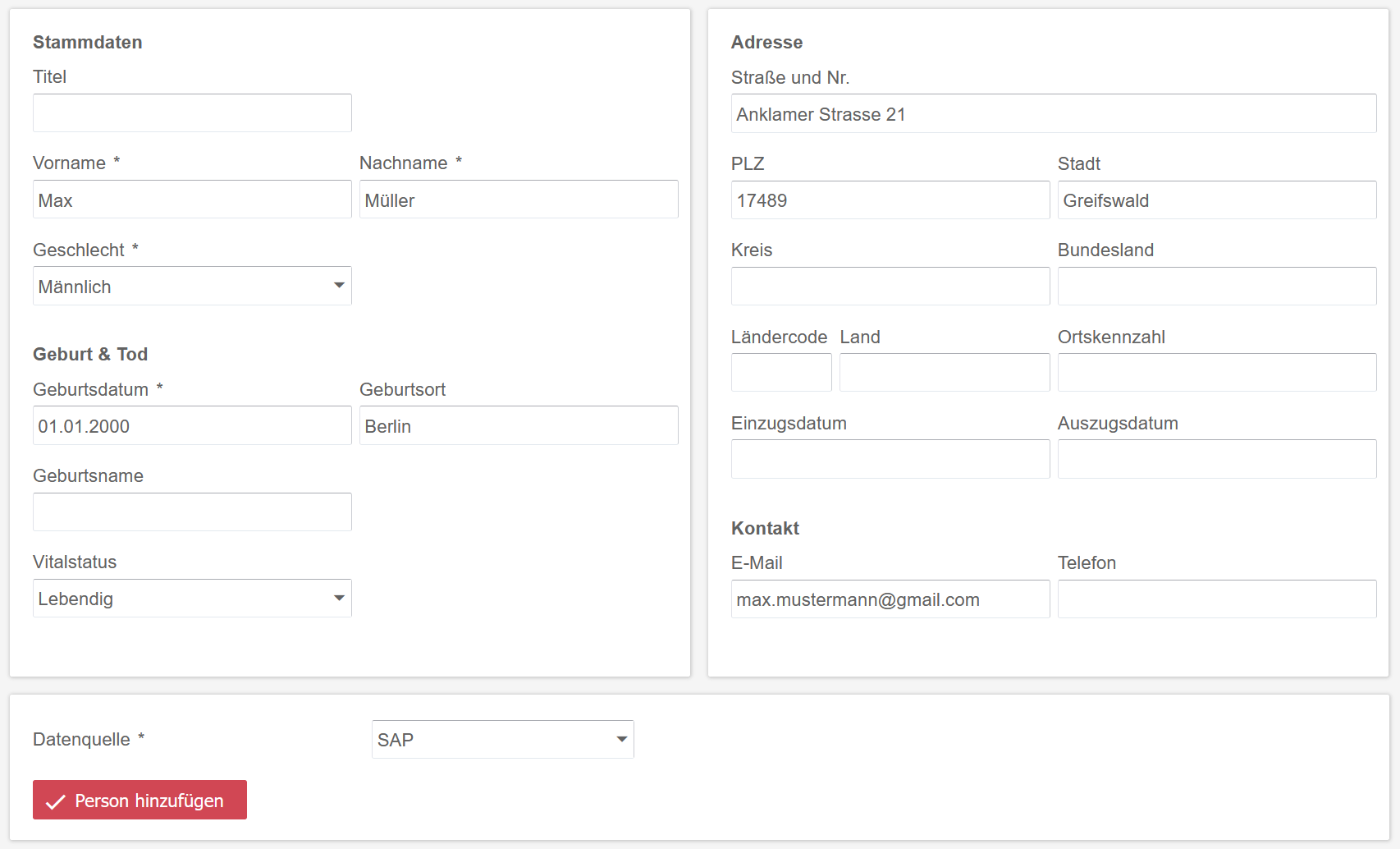
Personen erfassen
Personen können mit demographischen Eigenschaften, Kontaktadressen und projektspezifischen Parametern erfasst werden. Der Im- und Export von Excel-Listen erleichtert die Überführung von Bestandsdaten in den E-PIX® und die Zusammenarbeit mit anderen Softwareprodukten.
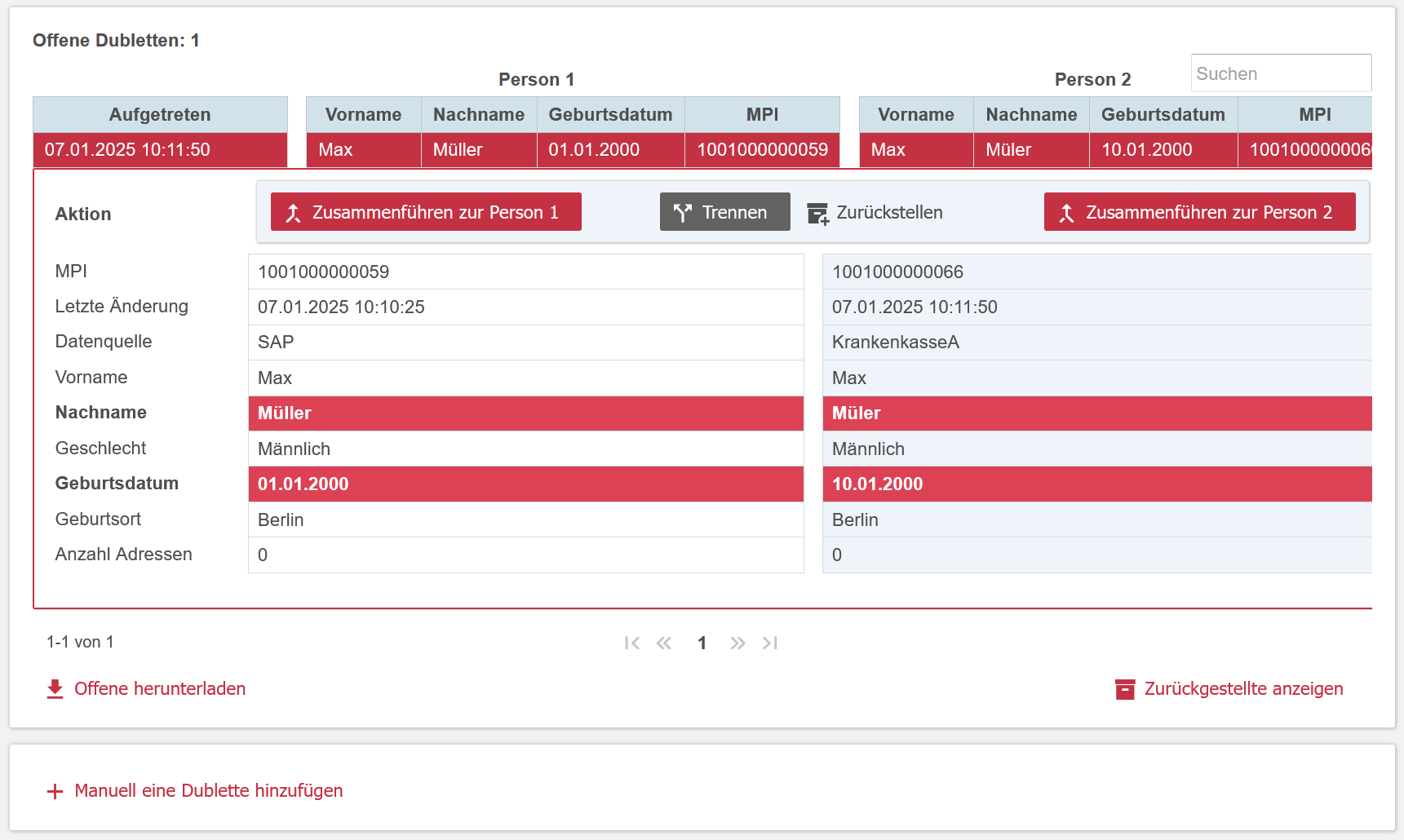
Doppler erkennen und bereinigen
Konfigurierbare Algorithmen ermöglichen mehrfache Einträge zur selben Person zu erkennen. Diese Doppler können automatisch oder manuell mithilfe der Oberfläche aufgelöst werden oder zur späteren Bearbeitung zurückgestellt werden.

Ereignisse protokollieren
Die Nachvollziehbarkeit von Record Linkage Ereignissen ist insbesondere bei der Zusammenführung von Personen wichtig. Das Protokoll einer Person gewährt Aufschluss über Matching-Ergebnisse, sowie die Anlage und Aktualisierung von Personendaten.
Download
Sie haben Interesse am E-PIX? Sie können diesen hier herunterladen und einfach mittels Docker starten. Alternativ erproben Sie den E-PIX in unserer Live-Demo.
Schnittstellen
Der E-PIX® wird mit TTP-FHIR Gateway ausgeliefert, welches das Anlegen und Suchen von Personen im HL7 FHIR®-Format ermöglicht.
Zugriff auf Oberflächen und Schnittstellen des E-PIX® kann mit Keycloak autorisiert werden (OAuth 2.0 + OpenID-Connect).

Integration des E-PIX® in Drittsysteme oder ETL-Prozesse mittels SOAP. Details sind im Handbuch zu finden.

Benachrichtigungen über Ereignisse können konfiguriert und automatisch an externe Systeme via JNDI, HTTP und MQTT verteilt werden.
Dokumentation
Anwenderprojekte
Die Lösungsbausteine der Treuhandstelle finden zunehmend Verbreitung in der Community. Immer mehr Konsortien, Standorte und Projekte haben sich bewusst für die Verwendung unserer Lösungen zur Realisierung ihrer individuellen Anwendungsszenarien entschieden. Zu den Anwendern gehören Register und Krebsregister, lokale Treuhandstellen der MII und des NUM, diverse Studienprojekte und ausgewählte DZGs.
Um Erfahrungen untereinander auszutauschen und Ergebnisse miteinander zu teilen haben wir den THS Community Dialog ins Leben gerufen.
Förderungen und Publikationen
Der E-PIX® ist frei verfügbar und wird seit 2009 von der Universitätsmedizin Greifswald (Institut für Community Medicine) entwickelt und wurde 2014 als Teil des MOSAIC-Projektes veröffentlicht (gefördert durch die DFG HO 1937/2-1). Ausgewählte Funktionen des E-PIX® wurden im Rahmen von MIRACUM (gefördert durch das BMBF 01ZZ1801M) und NUM (gefördert durch das BMBF 01KX2021) realisiert. Der E-PIX® wird fortlaufend anhand projektspezifischer Anforderungen und auf Grundlage der Rückmeldung aus der Anwender-Community weiterentwickelt.
Ausgewählte Publikationen
- A workflow-driven approach to integrate generic software modules in a Trusted Third Party
- Assessment of scalability and performance of the record linkage tool E-PIX® in managing multi-million patients in research projects at a large university hospital in Germany
- White Paper – Verbesserung des Record Linkage für die Gesundheitsforschung in Deutschland
- Integration of Trusted Third Party Software into an EDC System for Data Protection – Compliant Identity Management, Consent Management and Pseudonymization in Medical Research Studies